
Comment Google travaille sur son algorithme

Google, le site le plus visité au monde, soigne son algorithme de classement des pages dans les résultats des recherches. Il est intéressant de savoir, à la lecture de l'article de Saul Hansell dans le New York Time, que le PageRank, l'indice de popularité si connu, n'est jamais qu'un critère de score parmi de nombreux autres, et d'autre part que l'algorithme réel n'est pas quelque chose de figé, mais que les équipes de Google travaillent continuellement sur les analyses des résultats pour le corriger et contrôler le classement des pages.
Cela expliquera pour les webmasters pourquoi leur site fait quelquefois un bond en avant dans la liste des résultats et pourquoi aussi quelquefois il disparaît dans les profondeurs du classement sans raison, indépendamment de la pénalité dite "sandbox".
Le journaliste a eu l'occasion de passer une journée avec les ingénieurs de Google directement impliqués dans l'élaboration de l'algorithme, dans leur cadre de travail et de participer à leur réunion de travail.
On suit les indicateurs
Le travail de l'équipe est motivé par les plaintes des entreprises
dont le site est mal classé sans raison, et par leur propre analyse
des résultats. Il faut savoir que les 10000 employés possèdent
chacun un "buganizer", un outil pour signaler les problèmes
rencontrés dans une recherche et que toutes les remarques sont transmises
au team de l'algorithme.
On a constaté par exemple que les recherches sur "révolution
française" dirigeaient sur les articles de campagne électorale
parce que les candidats parlaient de "révolution"! La correction
à consisté simplement dans ce cas à donner plus de
poids aux termes "révolution française" ou "french
revolution" quand les termes sont accolés.
Les outils que l'on utilise
L'équipe dispose d'un outil spécial nommé "Debug",
qui fait apparaître comment les ordinateurs évaluent chaque
requête et chaque page Web. On peut voir ainsi quelle importance l'algorithme
attribue aux liens sur une page, et les corriger si besoin.
Une fois le problème identifié, une nouvelle formule mathématique
est mise au point pour traiter un cas de figure, et incorporée à
l'algorithme.
On se base sur des modèles
A coté du PageRank et autres signaux, l'algorithme fait appel à plusieurs modèles.
- Les modèles de langues: la capacité à comprendre les phrases, les synonymes, les accents, les fautes d'orthographe, etc.
- Les modèles de requêtes: il n'y a pas pas seulement la langue, mais comment elle est utilisée de nos jours.
- Les modèles de temps: certaines pages répondent mieux quand elles existent depuis 30 minutes, et d'autres quand elles ont subi l'épreuve du temps.
- Les modèles personnalisés: toutes les personnes ne recherchent pas les même choses (avec les mêmes mots, NdT).
(Voir références en bas).
La nouveauté est un dilemme
Un problème crucial pour l'équipe de développement,
est celui de la fraîcheur. Faut-il privilégier les nouvelles
pages, susceptibles de mieux refléter l'actualité, ou au contraire
les plus anciennes qui ont déjà démontré leur
qualité, par le nombre des backlinks notamment?
Google privilégiait toujours les dernières mais on s'est récemment
rendu compte que ce n'était pas toujours le bon choix, aussi a-t'il
fallu mettre au point un nouvel algorithme qui détermine quand l'utilisateur
a besoin d'informations nouvelles et quand elles doivent être stables
au contraire. Cela s'appelle la formule du QDF, "Query Deserves Freshness",
en français "requête sur la nouveauté".
On peut déterminer qu'un sujet est chaud quand les blogs se mettent
à en parler, ou quand il y a un afflux soudain de requêtes
sur ce sujet.
Il faut réaliser des snippets
Un groupe travaille sur les snippets. Il s'agit d'améliorer la présentation des résultats, en extrayant des informations au sujet d'un site et en l'affichant pour renseigner les utilisateurs sur le site avant qu'ils ne cliquent sur le lien.
Maintenir un index gigantesque
Google dispose de centaines de milliers d'ordinateurs pour indexer les
milliards de pages de tous les sites Web au monde... Le but est - indépendamment
de l'addition de pages nouvelles qui est continuel - de pouvoir mettre à
jour l'index tout entier en quelques jours!
Il est important de savoir que les centres de données stockent une
copie de toutes les pages du Web pour pouvoir y accéder plus rapidement.
Ajouter de nouveaux signaux à coté du PageRank
Le PageRank élaboré aux débuts de la compagnie par
Larry Page et Sergey Brin, est un indice correspondant aux nombres de liens
sur une page, gage de qualité pour celle-ci. Mais il est largement
dépassé. Google utilise maintenant 200 critères qu'il
appelle "signaux". Cela dépend à la fois du contenu
de la page, et de son évolution, des requêtes et du comportement
des visiteurs... mais tout cela est décrit en détail dans
le brevet du PageRank et la sandox.
A coté des signaux sur les pages et leur historique, Google utilise
des classificateurs sur les requêtes, dont le but est de restituer
le contexte de recherche, le cadre dans lequel elle se place. Par exemple,
veut-on rechercher un produit pour l'acheter ou se renseigner quelque chose?
L'élément le plus connu de notre classement est le PageRank, un algorithme développé par Larry Page and Sergey Brin, qui ont fondé Google. PageRank est toujours utilisé actuellement, mais il fait maintenant partie d'un système plus important.
Le billet qui est la source de cette citation (voir plus bas) nous apprend que le PageRank a été modifié en Janvier 2008, ainsi n'est-il pas immuable!
Une quête de diversité dans les résultats
Une fois que des pages ont été sélectionnées et classées, certaines devraient occuper les dix premières positions, les plus avantageuses, mais ce n'est pas fini. Google veut ajouter une diversité de point de vue, par exemple des blogs et des sites commerciaux aussi des pages moins bien classées seront ajoutées en tête de classement, la première de chaque catégorie étant ainsi promue.
Toujours améliorer l'algorithme
Des groupes travaillent à l'amélioration de l'algorithme, d'autres opérent sur l'évaluation des résultats. C'est en temps réel que l'on évalue la qualité des réponses de l'algorithme, pour vérifier la pertinence des réponses, surtout avec les contrôle des améliorations dès qu'elles sont apportées. C'est le travail de statisticiens de mesurer la qualité des résultats.
Un groupe est consacré au spam et tous types d'abus comme le texte caché. Ce 'webspam' groupe, on l'apprend, travaille de concert avec le groupe Google Webmaster Central qui fournit des aides et des outils aux webmasters.
Et tout n'est pas dit...
Les techniques de Google semblent plutôt académiques, avec ses signaux et classificateurs, si l'on compare avec les concurrents comme Microsoft qui utilise des réseaux neuronaux. Mais on ne sait pas tout, Google conserve encore beaucoup de secrets, ne voulant pas révéler aux concurrents toutes ses techniques.
Références: Blog officiel de Google. (Anglais). Une partie des informations ci-dessus viennent d'un article de Saul Hansell publié dans le New York Times.

Evolution de l'algorithme
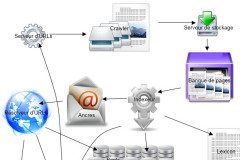
Anatomie du moteur de recherche